
First things first – What is dbt? – – dbt is a framework for data that can work magic when working with SQL queries. Let’s think of writing SQL in general scenarios where it’s so hectic or redundant of work, or when you want to deploy the same query but change things for different environments, or whenever there’s a change in a logical query block where it has to be modified in every piece of code it was used, or when there are too many tables to work and keep track the dependency between them, etc etc etc. These are all hectic jobs or simply mundane work when you are lazy, especially like me. So to simplify this, let’s look into what and how dbt plays a key role in this.
dbt in general stands for data build tool and it is a powerful transformation workflow that helps us get more work done while producing higher-quality results. It helps us modularize and collaborate on the models, version them, test, and document all the transformations before deploying them to production.
You see, for the kind of issues mentioned above, dbt works like a charm with its usability. With dbt, we don’t have to write DML or DDLs at all. We can simply just define a SQL select statement and dbt takes care of its materialization. We don’t have to write repeatable code, rather we can simply build reusable code that can be referenced anywhere down the line. We can use powerful macros which are simply like a function that can be utilized anywhere to make the process simpler. And moreover, when the models are set up in dbt and are being referred down the lane for further models, dbt automatically builds up a data lineage diagram making it more visible in terms of data flow.
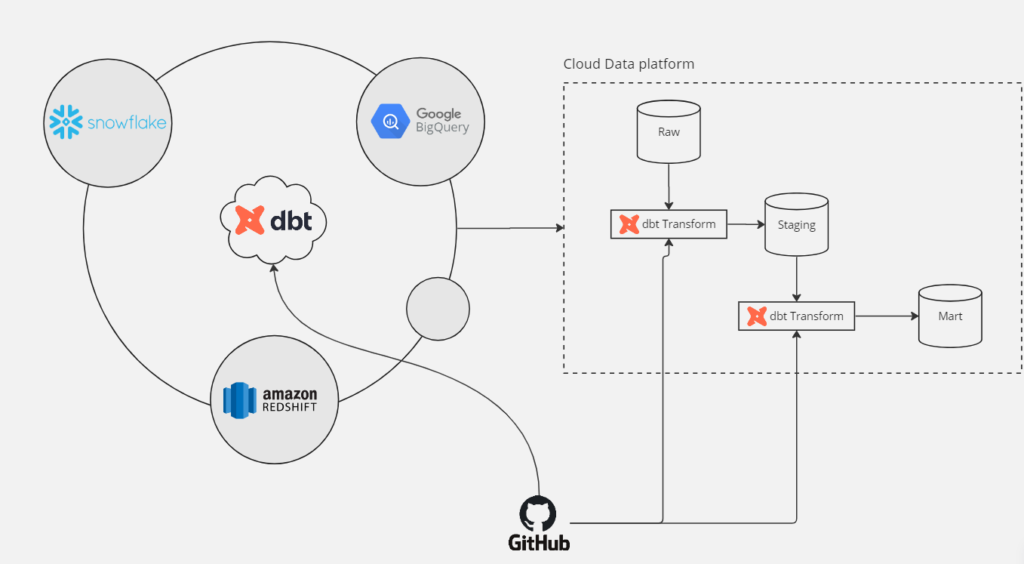
Where does dbt fit in my data architecture
dbt being a transformation tool, can be generally set up over the cloud data platform such as Snowflake, BigQuery, Redshift and many more it supports. In the ELT part of any ingestion tool, dbt can become a crucial partner to get the ‘T’ (transform) part done. Because of its usability and functionality, dbt has become popular and is being used with various cloud warehouses taking a step ahead. On the other hand, dbt seamlessly collaborates with Git whether working locally or in dbt Cloud even making the CI/CD pipelines look much simpler and easy deployable.
Another important aspect of dbt is that it addresses the testing of the data effectively. Generally, any incorrect and missing data leads to many issues in the analysis in realtime. With dbt, we can either create predefined or self-written tests or both to validate the quality of the data under process.
Terminologies and jargons
To warm up and get to know more about dbt, know the below terminologies so that you are ready for the dbt world.
Models: A dbt model is a SQL file that defines a transformation or a structured dataset within the data warehouse
Source: A source refers to the raw or untransformed data that is ingested into the warehouse
Dbt Project: It is a directory containing all the files and configurations necessary to define data models, tests, and documentation.
DAG in dbt: DAG is a Directed Acyclic Graph that represents a Data Lineage diagram showing the dependencies between models
Macros: Macros are reusable SQL code snippets which uses Jinja templating that can simplify and standardize common operations in dbt models, such as filtering, aggregating, or renaming columns. They can be defined and invoked within dbt models.
Seed: Seed is a type of dbt model that represents a table or view containing static or reference data
Snapshot: Snapshot refers to a type of dbt model that is used to track changes over time in a table or view
These are all the most important and basic parts of dbt to start ahead with. Once you start digging in, you will start finding a lot more interesting and fun aspects of around.